帮助文档
并行遍历(Parallel Foreach)
最新更新时间:2023-05-08 08:29:25
简介
并行遍历(Parallel Foreach)用于并行执行任务,对数据集上的元素并行执行相同的处理逻辑。实际并行数取当前剩余元素数与设置最大并行度之间较小值。
并行遍历的子流可以只读访问主流的变量和其他组件输出,但子流所做的修改均是不影响主流。
处理完成后,每个元素的处理结果按照原始顺序输出到 message 的 payload 中。并行遍历一般用于批量数据处理的场景,例如批量查询、批量导入数据等。
操作配置
参数配置
| 参数 | 数据类型 | 描述 | 是否必填 | 默认值 |
|---|---|---|---|---|
| 数据集 | string、list、dict、int | 待遍历的数据。
| 是 | 无 |
| 最大并行数 | int | 并行执行的任务数,取值范围为2 - 8 | 是 | 4 |
| 计数器 | string | 计数器是一个变量,该变量存储了当前的迭代次数,从0开始,这里填入变量名称,msg.vars.get('#计数器变量#')即可使用。 例如:当计数器变量使用默认值 counter 时,第1次循环,msg.vars.get('counter')值为0,第2次循环,msg.vars.get('counter')值为1。 | 否 | counter |
| 根信息 | string | 根信息同样是一个变量,这里填入变量名称,根信息中保存了主流的 message 信息。msg.vars.get('#根信息名称#').payload 即可访问主流的payload数据。当使用默认值rootMessage时,使用 msg.vars.get('rootMessage').payload 即可在 Parallel ForEach 的子流中访问主流的 payload 数据。 | 否 | rootMessage |
| 错误时终止 | bool | 若子任务发生错误,则会在已发起的子任务执行完成后终止遍历。 | 否 | False |
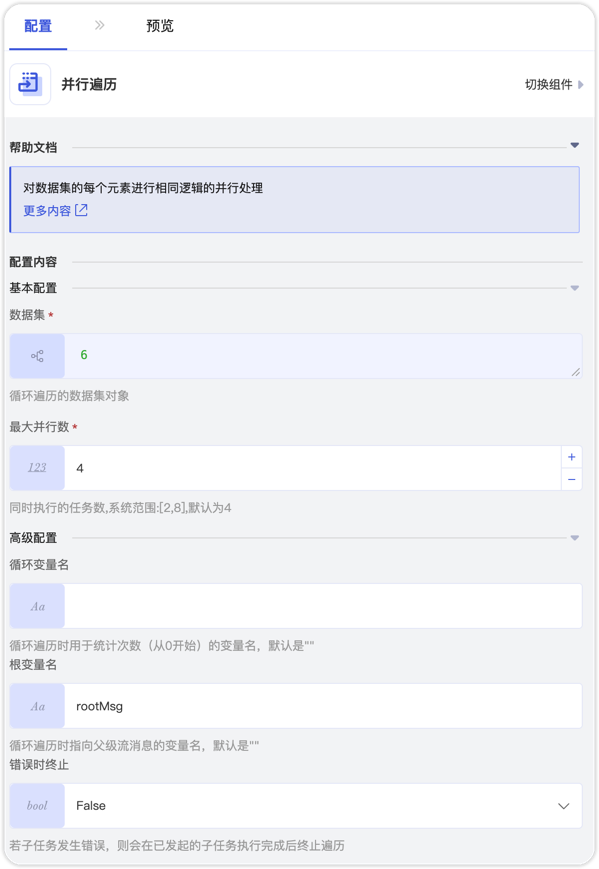
配置界面
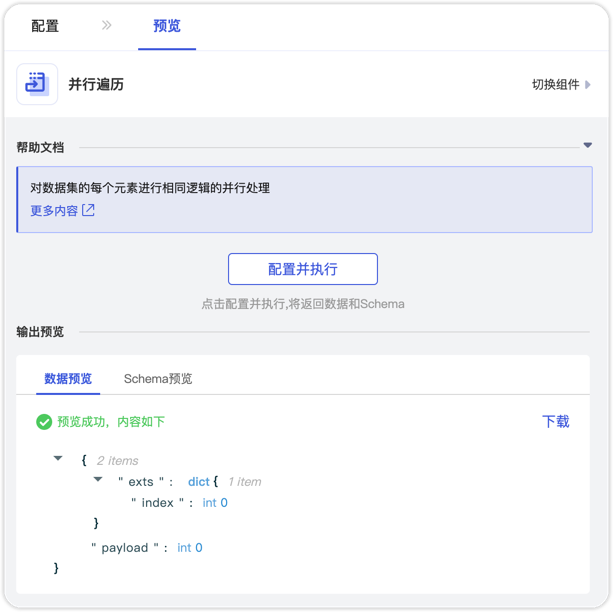
数据预览
| 预览字段 | 数据类型 | 描述 |
|---|---|---|
| payload | any | 每次遍历的输入值,属于数据集的其中一个元素。 |
| index | int | 每次遍历的位置,代表当前输入值在数据集中的下标位置,从0开始计数。 |
数据预览的内容仅为子流可见,子流中的组件可以直接使用遍历组件的Payload和index,如图所示:
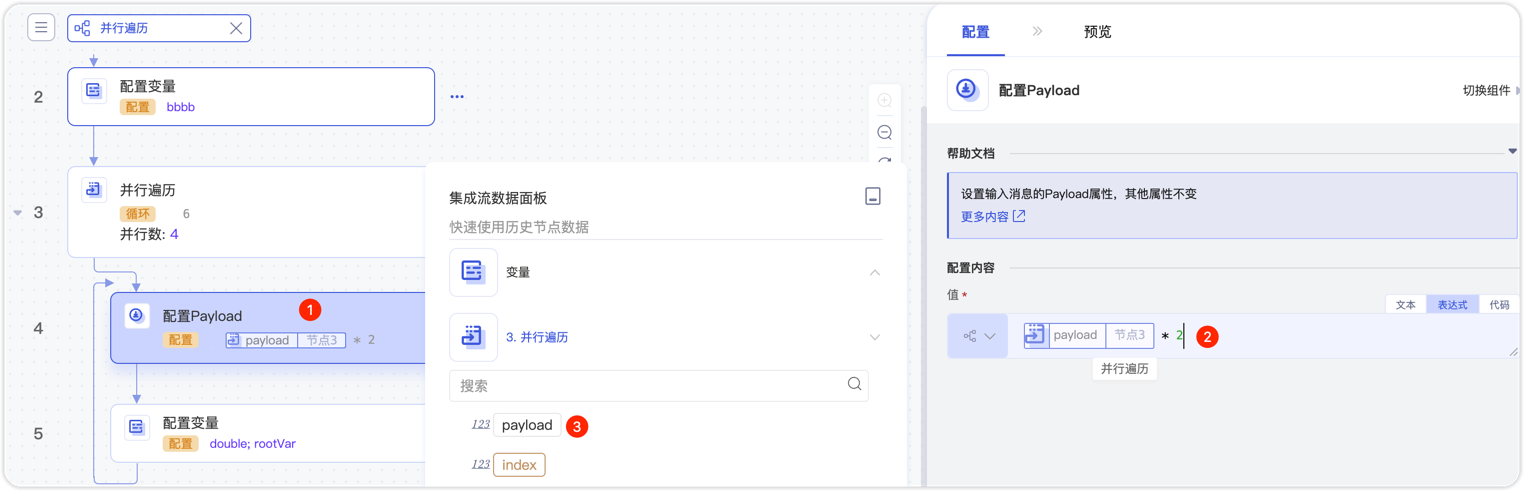
输入到子流中的 message
| message 属性 | 值 |
|---|---|
| payload | 数据集中的元素。例如:待迭代的数据集为[1,2,3],第一次循环,子流中 payload 的数据为1,第二次循环为2。 当迭代的数据集为dict类型{"key":"key1", "value":"value1"},第一次循环,子流中的 payload 为 value1,第二次为 value2。 |
| error | 空 |
| attribute | 空 |
| variable | 继承主流中的 variable 数据,同时新增两个变量,一个是计数器,一个是根信息,若用户使用默认值,可使用表达式 msg.vars.get('counter')和msg.vars.get('rootMessage')访问。 若 For Each 中使用了 Set Variable,则在子流执行过程中,新增的变量也会添加到 varaible 中。 |
输出
并行遍历的输出结果中,不会包含处理逻辑中使用的 variable 变量,最终输出的只有 payload 里的数据,输出的 payload 是个 list 类型变量,里边包含了原始数据集中每个元素迭代处理的结果,顺序与原始数据集一致。attribute 的值继承自上一个组件。
组件输出的 message 信息如下:
| message 属性 | 值 |
|---|---|
| payload | list 类型,包含了每个数据的处理结果,输出顺序与原始的输入顺序一致 |
| error |
|
| attribute | 继承 Parallel ForEach 上一个组件的 attribute 信息 |
| variable | 继承 Parallel ForEach 上一个组件的 variable 信息 |
输出样例如下: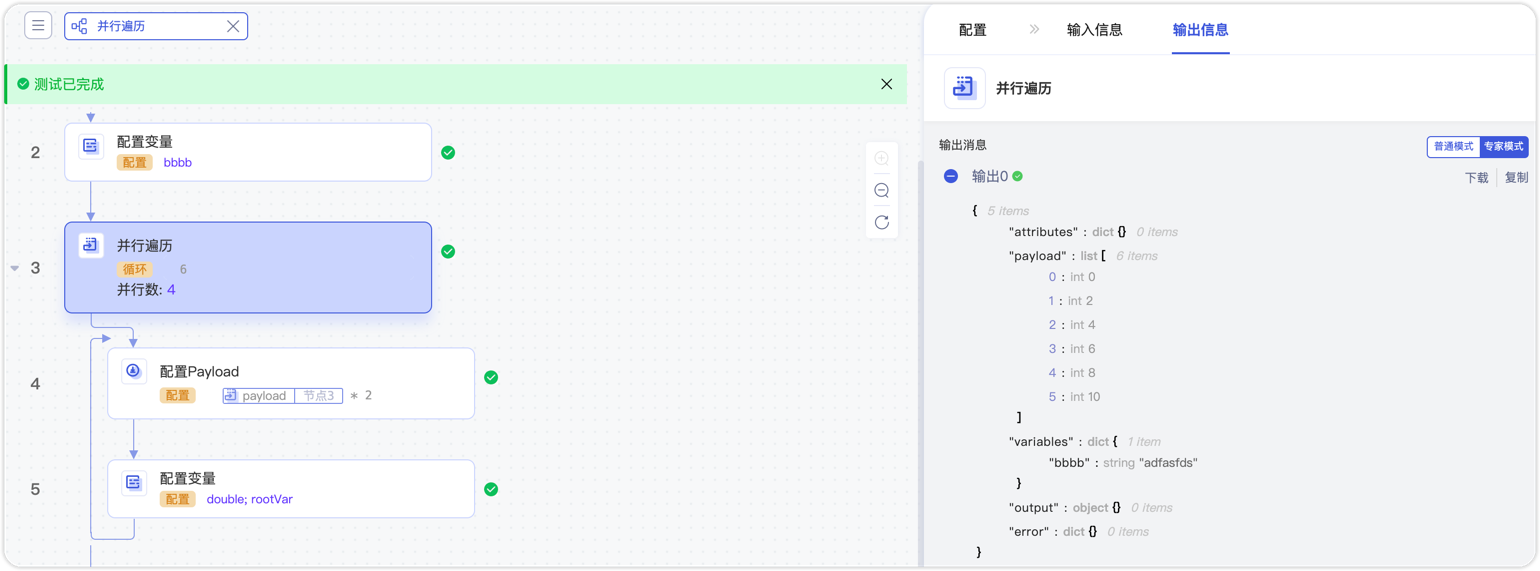
案例
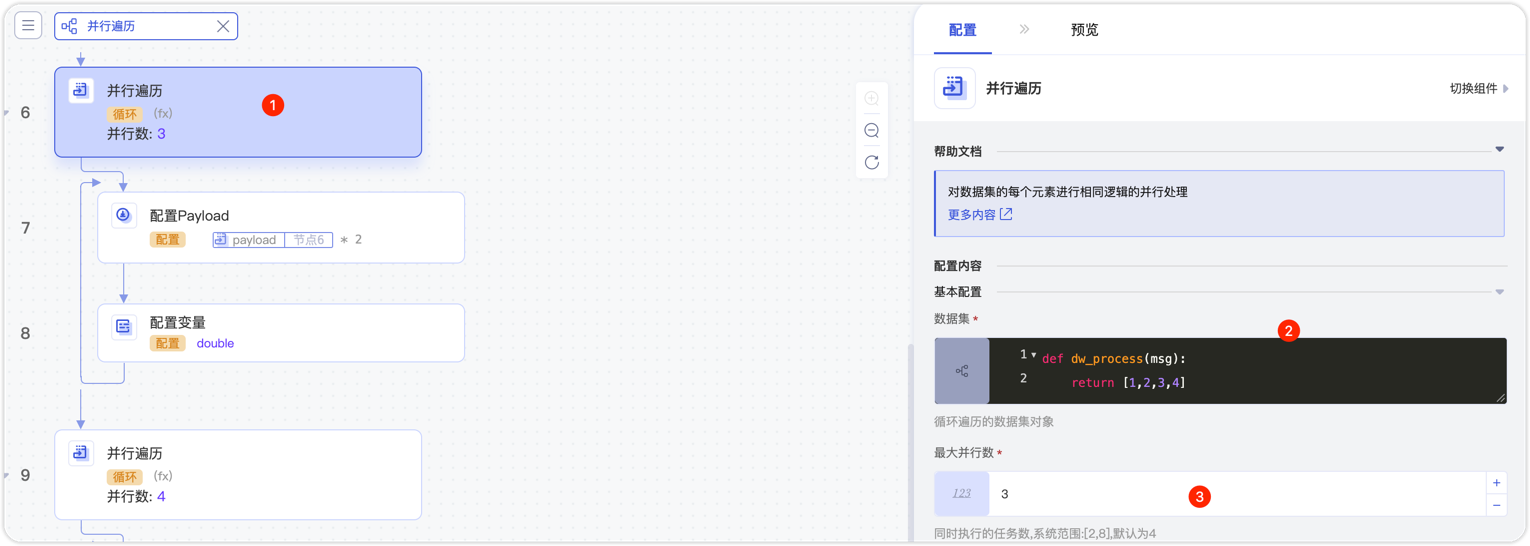
本案例中,我们使用并行遍历对列表中的数据统一进行乘2操作,原始的数据集为 [1,2,3,4]。
添加并行遍历组件,配置数据集[1,2,3,4],并设置并行度为3。
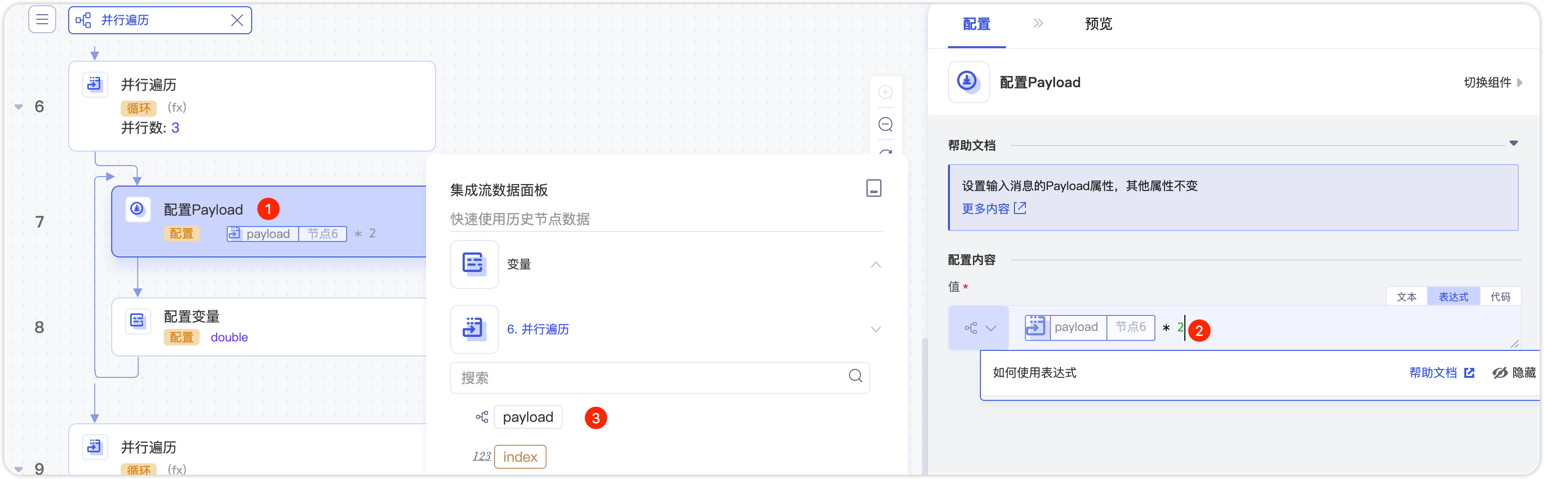
在并行遍历中加入配置 Payload 组件,对子流 Payload 执行乘2操作。
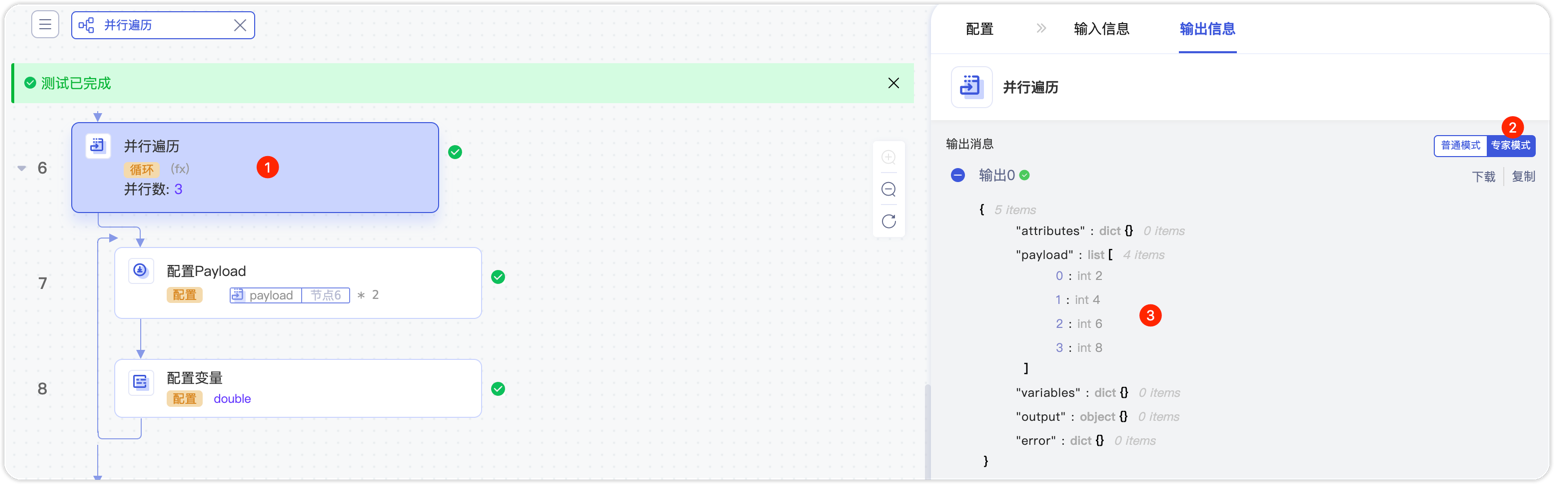
输出结果。
如果您在文档使用中遇到问题或者有改进建议,请点击 在线反馈

